本文总结了 Andrej Karpathy 前不久关于 LLM 的分享 Deep Dive into LLMs like ChatGPT,用于部门内部分享,也可以理解为一个 TL;DR 版本。强烈建议观看原视频。
预训练(Pre-training)
互联网
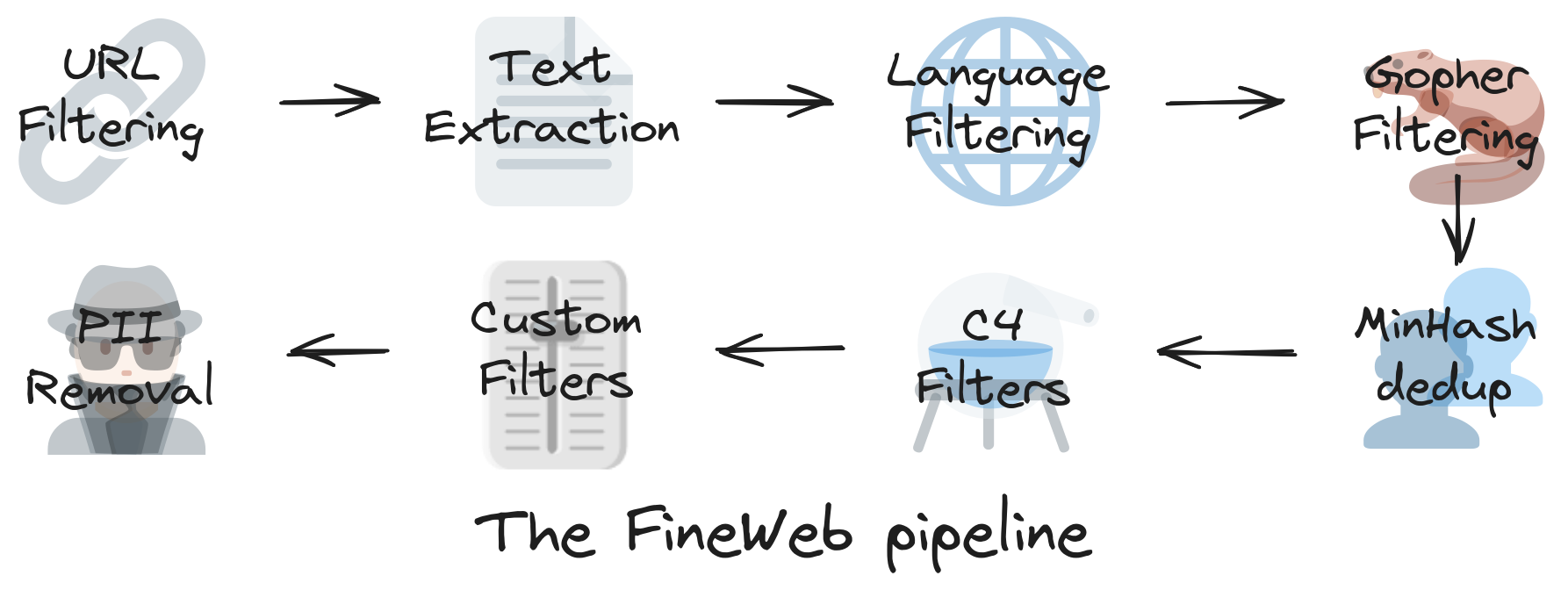
FineWeb 是一个包含超过 12 亿个网页的数据集。
LLMs 首先爬取互联网以构建大量文本数据集。这些文本的问题在于原始数据充满噪音,有大量重复、低质量、无关紧要的文本内容。在使用这些数据训练 LLMs 之前,需要进行清洗过滤。
数据清洗后,仍然需要压缩才能适用于模型训练。
分词(Tokenization)
分词是在处理之前,模型是如何将文本分解为较小的零件(Token)的。该模型没有存储原始单词,而是将它们转换为代表重复模式的 ID。
分词为了使用尽可能短的序列来实现更高压缩率。
一种流行的技术是字节对编码(BPE)
字节对编码是一种简单的数据压缩形式,这种方法用数据中不存在的一个字节表示最常出现的连续字节数据。
好的分词数量的选择有利于模型。例如,GPT-4 使用 100,277 个 Token 数量。它完全取决于模型创建者。
Tiktokenizer 是一个可视化工具帮助理解分词效果。
神经网络训练(Neural Network Training)
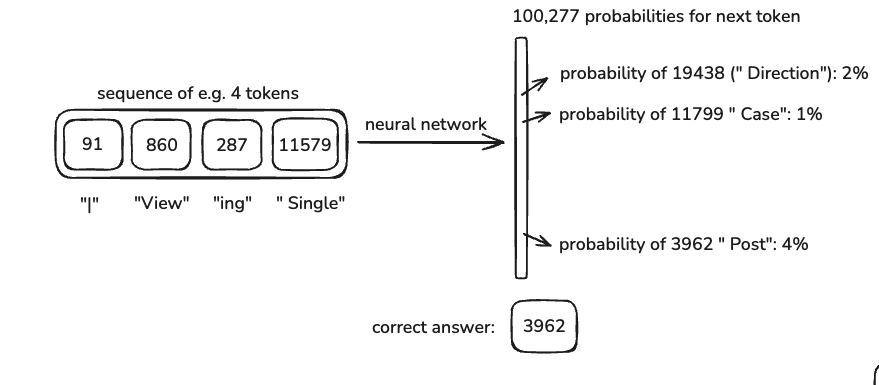
分词完成后,它们会被喂给神经网络:
- 采用一组 Token 组成上下文窗口(Context Window)
- 经过模型预测得到下一个 Token
- 根据结果调整模型中的权重
- 随着训练的增加模型学会更好地预测
更长的上下文意味着模型可以有更多“记忆”,同时也会增加计算成本。
神经网络内部(Neural Network Internals)

在模型内部,数十亿个参数与输入 Token 同时计算,生成下一个 Token 的概率分布:
- 模型参数和输入变量的计算方式由复杂的数学方程定义。
- 模型体系结构旨在平衡速度,准确性和并行化。
- 可视化参考
推理(Inference)
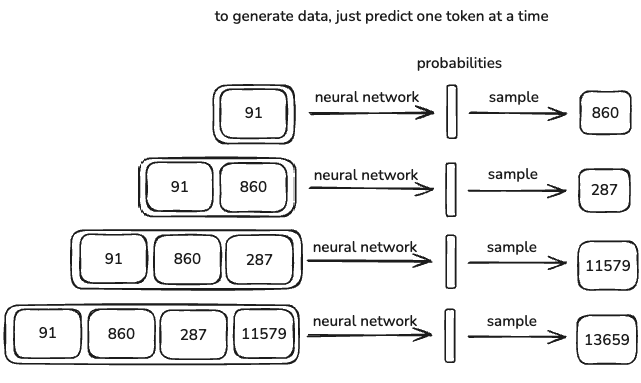
LLMs 不会产生确定性的输出,它们是随机的。这意味着每次运行模型时,输出都会略有不同。
- 模型不仅重复了经过训练的内容,还会根据概率生成响应。
- 在某些情况下,响应将与培训数据中的某些内容完全匹配,但是大多数情况下,它会生成遵循类似模式的新事物。
这种随机性是 LLMs 有时候看起来有创造力的原因,也是它们有时会产生幻觉的原因。
例子:重现 gpt2 训练
Openai 于 2019 年发布的 GPT-2 是基于 Transformer 的早期 LLM。它具有:
- 16 亿参数
- 1024 token 上下文长度
- 通过约 1000 亿个 token 训练
- 培训成本为 40,000 美元
今天(2025/2)训练的效率已大大提高。成本也降低为数百美元:
- 更好的预训练数据提取技术:清洗后的数据集帮助模型更快训练。
- 更强的硬件和优化的软件:相同结果所需的计算较少。
Karpathy 复现相关链接: https://github.com/karpathy/llm.c/discussions/677
开放的基础模型
一些公司培训大型语言模型(LMS) ,并免费发布基本模型。基本模型本质上是一种原始的,预先训练的LM,它仍然需要微调或对齐才能实际上有用。
基础模型经过互联网规模数据的培训,这意味着它们会尝试补充原始数据,但与人类意图缺乏一致性。
模型的发布需要什么?
- 运行(推理)模型的代码:定义模型推理的步骤(model.py)
- 模型权重:模型的数十亿个参数
基础模型的本质
- 这是一个 token 级别的互联网文本模拟器
- 它是随机的,每次运行时,都会得到不同内容
- 它“梦想”互联网文档
- 它还可以从记忆中逐字朗诵一些训练语料
- 模型的参数有点像互联网的的有损压缩编码
- 您已经可以通过提示来将其用于应用程序
- 例如翻译:应用程序通过构建几次提示(few-shot)并利用“上下文学习”能力。
- 例如助手:以结构化的方式提示他们。
- 但是我们可以做得更好…
有监督的微调(Post-Training: Supervised Finetuning)
对话

一旦基本模型经过了互联网数据的训练,下一步就是后训练。在这里,我们用人/助手对话替换互联网数据集,以使模型更可对话和有用。
- 最初的训练集来源于人工标注。
- 预训练需要几个月,但是后训练要快得多。它可能需要几个小时。
- 模型的算法保持不变,我们只是在微调现有参数。
对话协议/格式
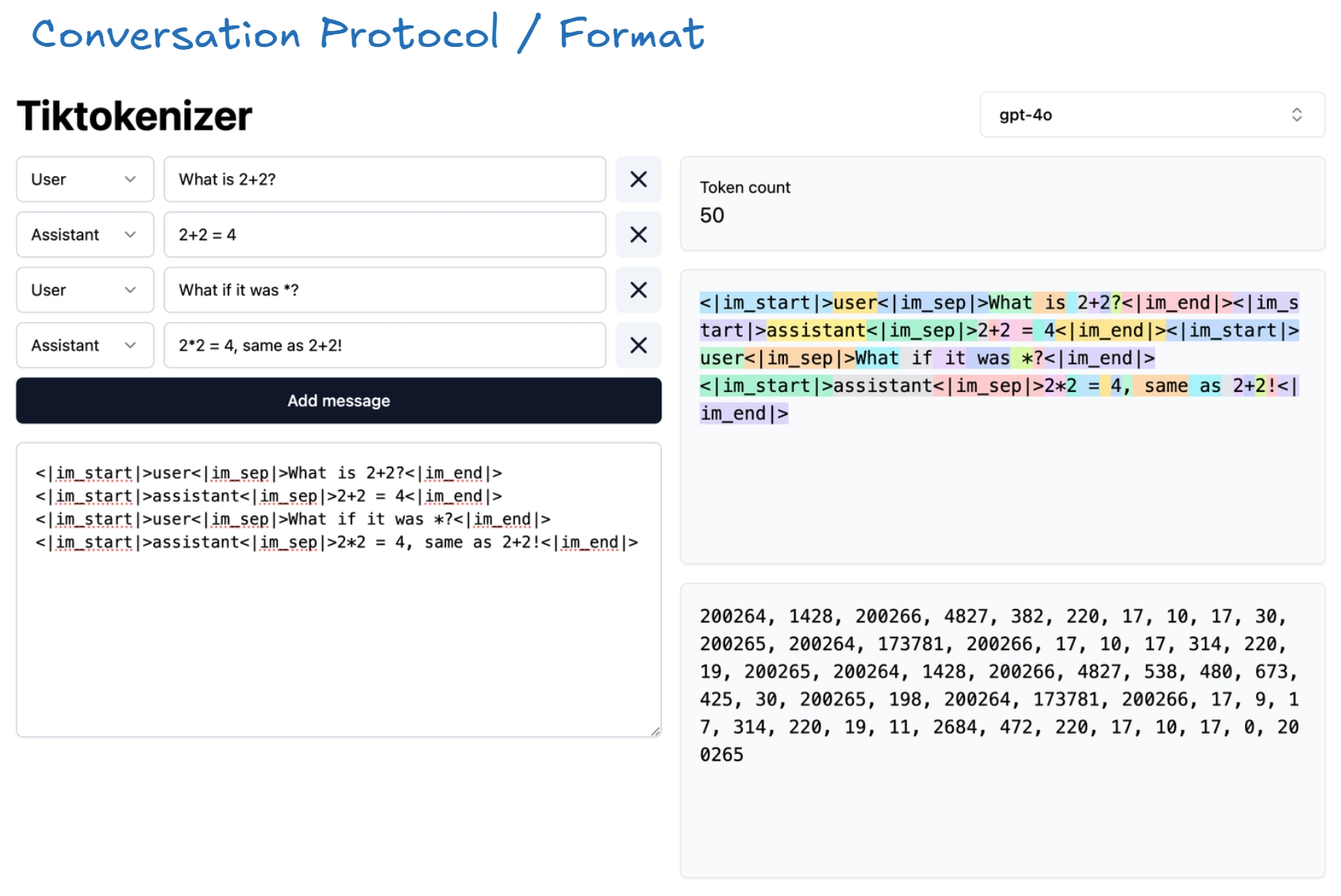
要训练如何处理来回对话的模型,我们需要使用聊天模板。这些模板定义了对话的结构,并让模型知道哪个部分是用户输入,哪个部分是助手响应。
<|im_start|>和<|im_end|>是有助于构建对话的特殊令牌。- 模型在预训练不会使用这些新的令牌,而是在后训练引入他们。
1 | messages = [ |
对于使用标准 chatml 格式的模型示例:
1 | <|im_start|>system<|im_sep|>You are a helpful assistant<|im_end|><|im_start|>user<|im_sep|>What is 4 + 4?<|im_end|> |
对话数据集
早期培训数据集由人类手工编写,这样的后训练数据集就像 OASST1。
现在大多数的对话数据集都是模型生成的,像 Ultrachat 这样的模型可以生成对话,从而使模型可以在没有太多人类输入的情况下改进。
幻觉
LLMs 的一个主要问题是容易产生幻觉,即错误或者不理想的回答。
为什么会发生幻觉:
- 在预训练后,模型学习到的是必须始终给出答案。
- 即使问题没有意义,该模型也试图产生回应,而不是说:“我不知道。”
如何处理这些幻觉:
添加训练数据处理特殊问题(以 Llama 3 为例)
- 提取训练数据的片段。
- 使用 Llama 3 生成有关它的事实问题。
- 让 Llama 3 产生答案。
- 根据原始数据对响应进行评分。
- 如果不正确,训练模型以识别和拒绝不正确的响应。
本质上,此过程教会模型认识自己的知识限制。
引入特殊的 Token 和工具实现搜索
1 | <|im_start|>user<|im_sep|>Who is Orson Kovacs?<|im_end|> |
通过反复的训练,模型了解到,如果他们不知道某事,他们应该查找它而不是编造一些回复。
“模糊的回忆”与“工作记忆”
- 模型参数存储模糊的回忆(例如一个月前记住某些内容)。
- 上下文窗口作为工作记忆的功能,使模型访问新信息。
这就是为什么 RAG 表现优秀的原因:如果模型可以直接访问相关文档,则无需猜测。
模型自我认知
如果问一个基本模型一个关于它是谁的问题,那么它大概率可能产生幻觉。
如何解决自我认知的问题?
- 添加自我认知到训练数据:添加对话数据对模型进行微调,如 olmo-2-hard-coded。
- 使用系统消息(system messages):在每个对话开始时,请提醒其身份。
模型需要 token 思考
LLMs 不像人类那样推理。它们依次生成 token,这意味着他们需要结构化的生成内容才能正确思考。
不好的例子:
1 | Human: Emily buys 3 apples and 2 oranges. Each orange costs $2. The total cost of all the fruit is $13. What is the cost of apples? |
好的例子:
1 | Human: Emily buys 3 apples and 2 oranges. Each orange costs $2. The total cost of all the fruit is $13. What is the cost of apples? |
- 如果模型直接给出答案,大概率是在猜测。
- 如果它逐步推理得到解决方案,则更可靠。
- 模型将问题分解为更小的步骤。由于模型中的层数有限,因此无法无限地处理一个 token 输出。将问题分解为更小的步骤可使模型以更有可能得出正确答案的方式处理问题。
- 模型的推理过程一般不需要提示词干预。
一些其它常见幻觉
- 模型不会数数
“strawberry” 里有几个 “r”
- 模型的输入输出的形式都是 token,无法处理字符个数。
- 模型本身不具备数数的能力。
- 比大小问题
9.11 和 9.9 哪个大
- 模型被版本号等场景分散注意力。
解决方案:通过引入工具(网页搜索、Python解释器等)解决
强化学习(Post-Training: Reinforcement Learning)
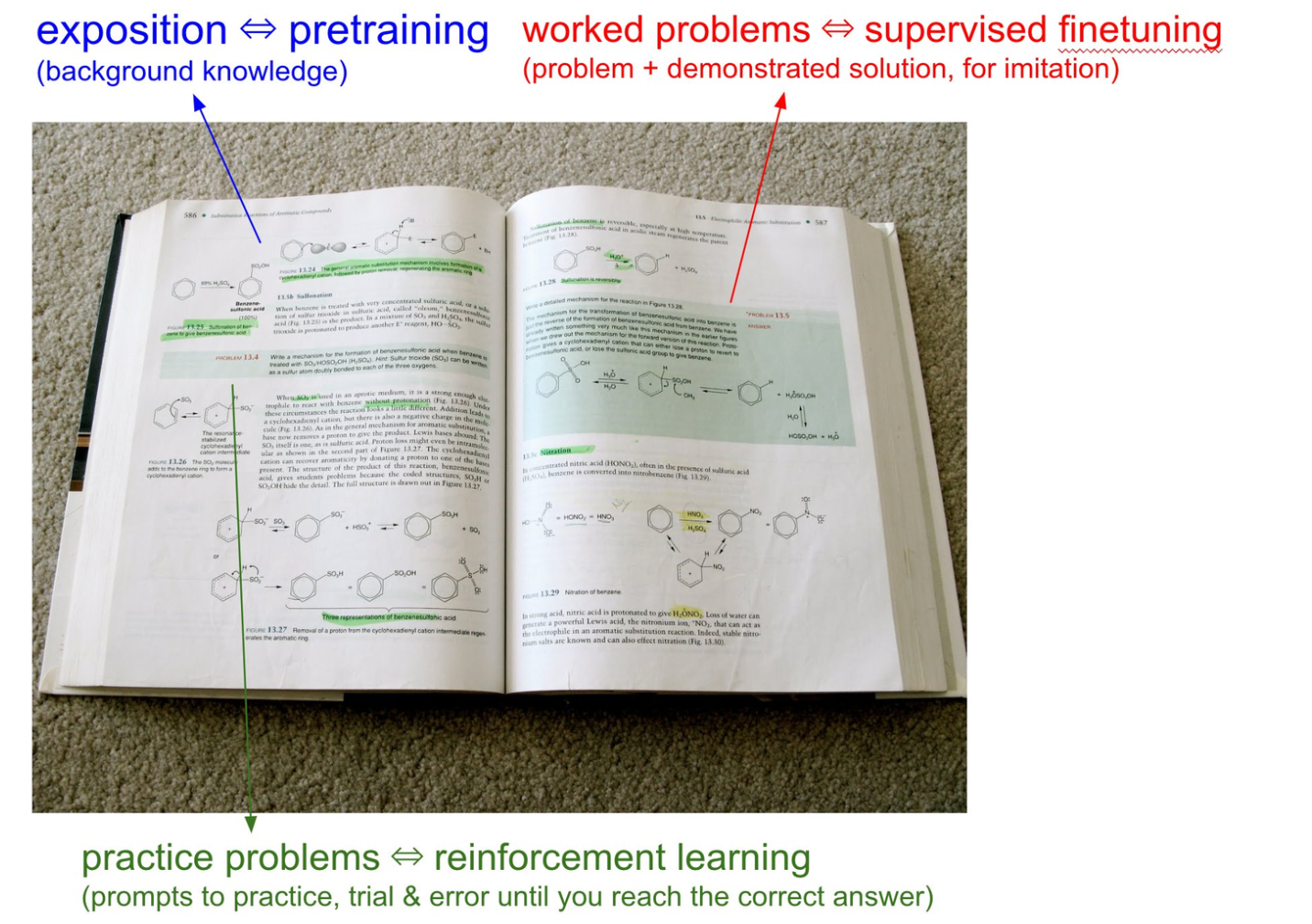
即使模型接受了互联网数据的培训,它仍然不知道如何有效地使用其知识。
- 有监督的微调(SFT) 教会它模仿人类的反应。
- 强化学习(RL) 通过反复试验改善它。
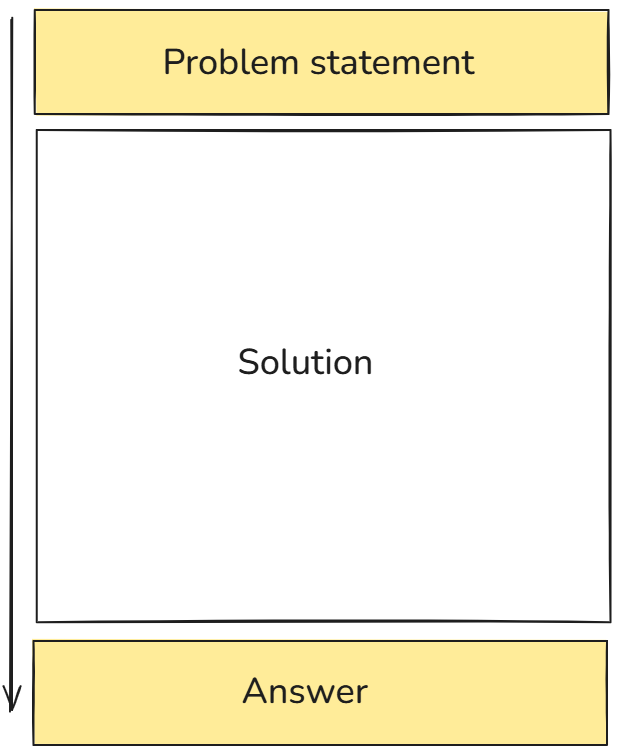
现在我们已经有了问题描述(prompt)和最终答案。
我们的目标是通过练习,从问题描述逐步推导到最终答案的过程,并将这些方法“内化”进模型中。
强化学习(RL)
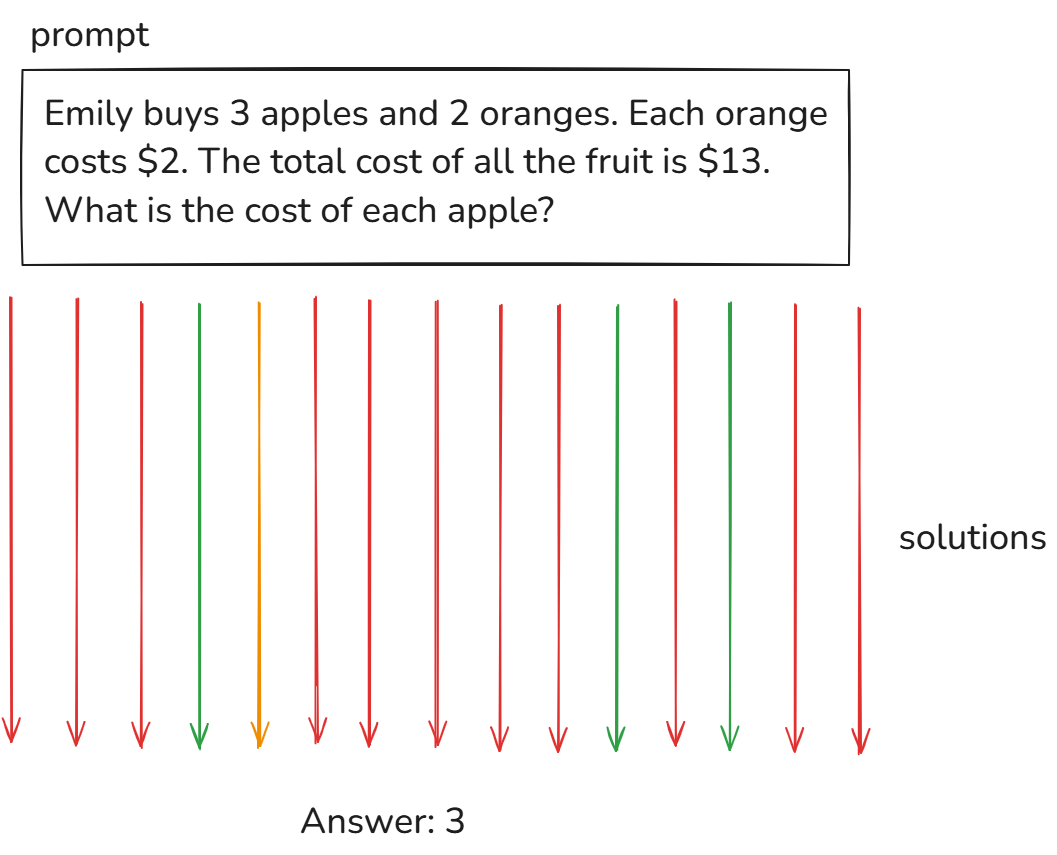
RL 训练的流程如下:
- 生成 15 条推理过程
- 只有 4 条得到正确答案
- 获取所有(最)正确的解法
- 用这些解法训练
- 重复上述步骤多次
此过程无需人工参与。模型会针对同一问题生成不同的解决方案,有时甚至多达数百万个。然后,它会比较这些解决方案,选出能够得出正确答案的解决方案,并针对获胜的解决方案进行训练。
DeepSeek
预训练和后训练过程定义得非常明确,但强化学习过程仍在大量积极研究中。OpenAI 等公司对此进行了大量研究,但并未公开。这就是为什么 DeepSeek 的发布如此重要。
Deepseek 论文中的一个例子向我们展示了随着时间的推移,模型能够使用更多的标记来提高推理能力。

可以看到模型在这里有了这个“aha”时刻,这不是可以通过在数据集上进行训练明确地教给模型的东西。这是模型必须通过强化学习自己弄清楚的东西。这种技术的优点是,模型在推理方面变得更好,但缺点是它为此消耗了越来越多的 token。
AlphaGo
我们从这篇关于AlphaGo论文中可以了解到,强化学习实际上可以帮助模型比人类更善于推理。模型不仅仅是试图模仿人类,它还会通过反复试验想出自己的策略来赢得比赛。
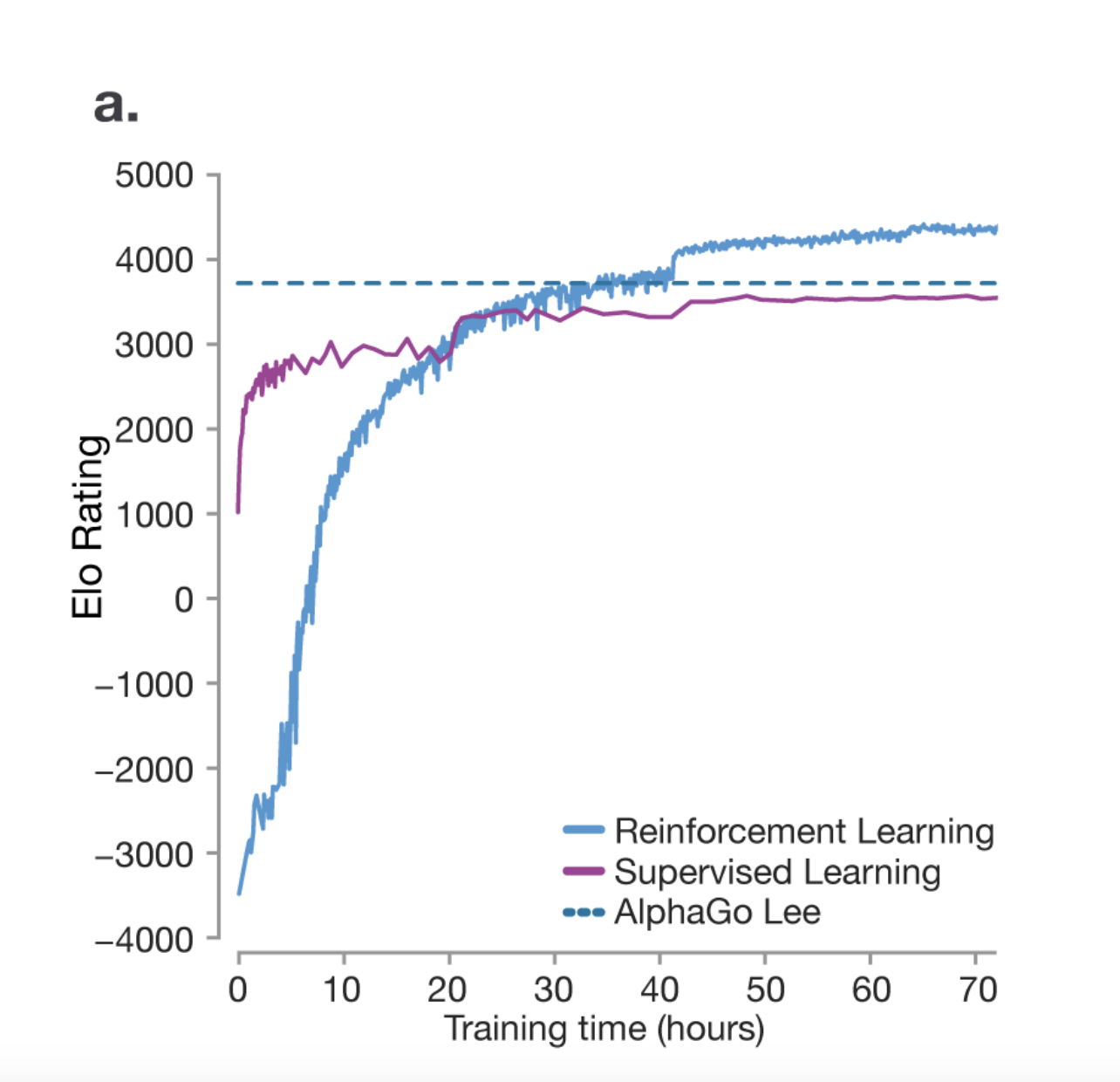
在 AlphaGo 的比赛中,一个非常独特的现象是第 37 步。这一步不属于训练数据,但模型想出了自己的策略来赢得比赛。研究人员预测,人类下出这一步的概率是万分之一。所以你可以看到模型如何能够想出自己的策略。
RL 仍未得到充分探索,该领域正在进行大量研究。如果有机会,机器人完全有可能想出一种自己的语言来表达自己的思想和想法,因为它发现这是表达思想和想法的最佳方式。
RLHF(Reinforcement Learning from Human Feedback)
在可验证域中,很容易将人类排除在 RL 过程之外。LLMs 可以充当自身表现的评判者。然而,在无法验证的领域,我们需要将人类纳入其中。
例如,对于提示写一个关于鹈鹕的笑话 ,找到一种自动判断笑话质量的方法并不容易。LLM 可以毫无问题地生成笑话,但无法大规模判断其质量。

此外,大规模地将人类纳入这一训练过程是不现实的。这就是 RLHF 的用武之地。可以在本文中阅读更多相关信息。

为了大规模进行 RLHF,需要训练一个单独的奖励模型。首先使用人工来判断它给予响应的排名,然后使用它来训练奖励模型,直到您对结果满意为止。完成后,您可以使用奖励模型来判断大规模生成的响应的质量。
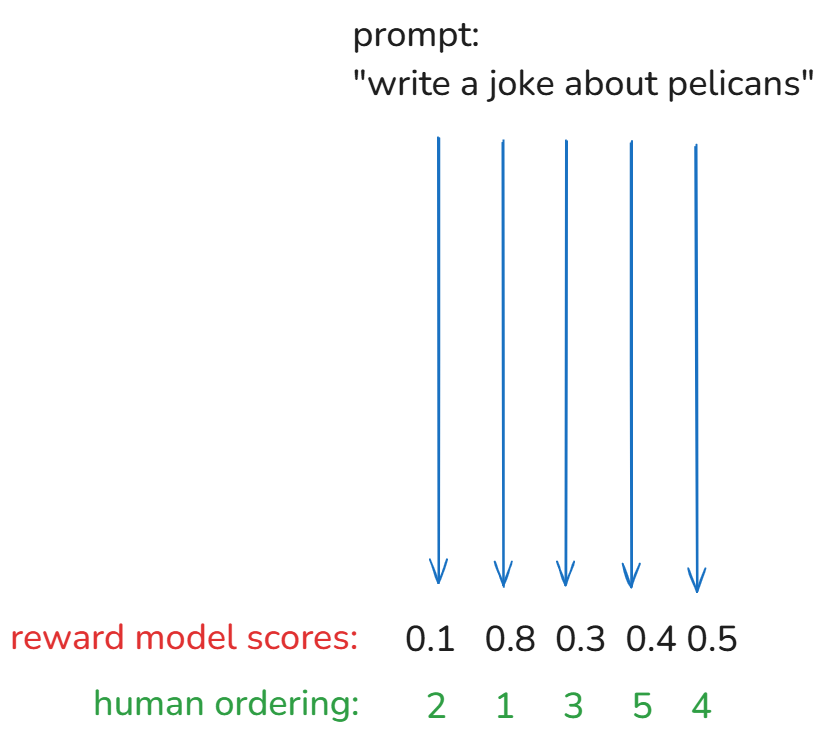
RLHF 的好处:
- 在无法验证的领域(例如写笑话或总结)中启用 RL。
- 通常通过减少幻觉并使反应更像人类来改进模型。
- 利用“鉴别器-生成器之间的差距”——人类发现评估答案比生成答案更容易。
- 例如:“写一首诗”与“这五首诗哪一首最好?”
RLHF 的缺陷:
- 奖励模型只是对人类偏好的模拟,而不是真实的人类。这可能会产生误导。
- RL 可以欺骗系统,产生利用奖励模型中的弱点的对抗性示例。
- 示例:经过 1,000 次更新后,模型的“关于鹈鹕的最佳笑话”可能完全是胡说八道(例如, “the the the the the the the the” )。
- 这被称为对抗性机器学习。由于有无数种方法来欺骗系统,因此过滤掉不良反应并不是一件简单的事情。
- 为了防止这种情况,奖励模型训练的上限是几百次迭代——超过这个上限,模型就会开始过度优化,性能就会下降。